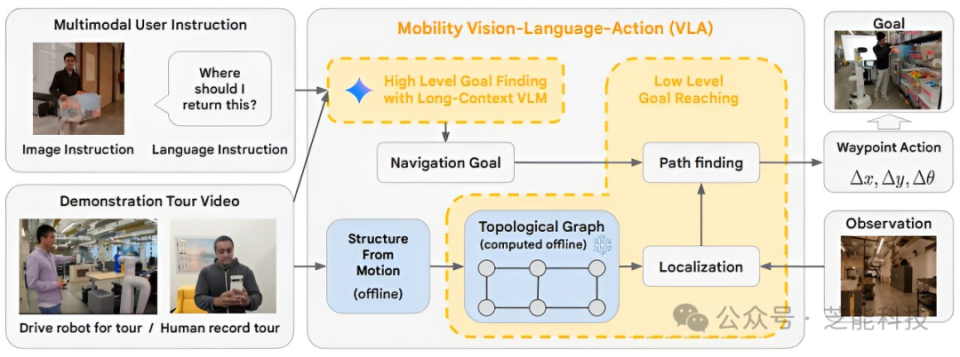
具身智能旨在讓智能體在物理世界中通過感知、決策和行動實現目標,視覺-語言-動作(VLA)模型作為其核心技術,近年來備受關注。
VLA模型能夠處理視覺、語言和動作信息,使智能體理解人類指令并執行任務。
我們總結了主流VLA方案,包括基于經典Transformer、預訓練LLM/VLM、擴散模型等類型,代表性開源項目和核心思想,方案間的差異與共識,并探討了數據稀缺、運動規劃、實時響應等挑戰及未來發展方向。也是為接下來中國VLA模型的涌現做一些梳理,希望為具身智能研究提供一些參考。
01
● VLA模型通過多種技術路徑實現視覺、語言和動作的融合,其方案多樣,各具特色。
◎ 基于經典Transformer結構的方案,如ALOHA(ACT)系列、RT-1、HPT等,利用Transformer的序列建模能力,將強化學習軌跡建模為狀態-動作-獎勵序列,提升復雜環境下的決策能力;
◎ 基于預訓練LLM/VLM的方案,如RT-2、OpenVLA等,將VLA任務視為序列生成問題,借助預訓練模型處理多模態信息并生成動作,增強泛化性和指令理解能力;
◎ 基于擴散模型的方案,如Diffusion Policy、RDT-1B等,通過去噪擴散概率模型生成動作,適用于高維動作空間和復雜動作分布;
◎ LLM+擴散模型方案,如Octoπ0等,結合LLM的多模態表征壓縮與擴散模型的動作生成能力,提高復雜任務中的性能;
◎ 視頻生成+逆運動學方案,如UniPiRo、BoDreamer等,先生成運動視頻再通過逆運動學推導動作,提升可解釋性和準確性;
◎ 顯示端到端方案直接將視覺語言信息映射到動作空間,減少信息損失;
◎ 隱式端到端方案,如SWIM等,利用視頻擴散模型預測未來狀態并生成動作,注重知識遷移;
◎ 分層端到端方案結合高層任務規劃與低層控制,提升長時域任務的執行效率。
這些方案通過不同架構和技術手段,為具身智能在機器人控制、任務執行等場景中的應用奠定了基礎。

● 目前主要 VLA(視覺語言動作)模型
◎ Helix(Figue AI):Helix 是全球首個集成視覺感知、語言理解與運動控制的人形機器人 VLA 模型,采用創新的雙系統架構:70 億參數的主模型負責多模態決策(7-9 Hz),8000 萬參數的運動 AI 實時生成精確動作(200 Hz)。
其突破包括支持 35 軸自由度的實時控制、多機器人協作以及無需特定訓練的未知物體處理能力。
該模型通過僅 500 小時監督數據完成訓練,運行于嵌入式 GPU,專注家庭場景(如整理冰箱、物品分類),旨在推動人機交互的自然化與普及化。
◎ RT-2(Google DeepMind):RT-2 是基于 Transformer 的 VLA 模型,通過互聯網文本和圖像數據學習通用概念,并將其轉化為機器人動作。
相比前代 RT-1,RT-2 在新任務泛化能力上顯著提升,尤其擅長通過語義理解執行復雜操作。
其典型應用為 Google Project Mariner,作為瀏覽器擴展的實驗性 AI 代理,實現自主網絡導航與任務執行,展現了 AI 從虛擬到物理世界的跨領域遷移潛力。
◎ Meta 的 AI 系統:Meta 正大力投資 AI 控制的人形機器人研發,其現實實驗室團隊聚焦消費者級機器人的傳感器、軟件平臺及共享 AI 系統開發。
該戰略旨在降低行業技術門檻,使第三方制造商也能接入 Meta 的技術生態。
盡管具體產品尚未公開,但公司強調通過開放協作推動機器人技術的普惠化,未來或重塑家庭與工業場景的人機協作模式。
◎ 蘋果的機器人 AI:蘋果的機器人研發尚處早期階段,重點探索人機交互技術,尤其關注機器人在家庭場景中的自然溝通與協作能力。
據分析師預測,其首款人形機器人或于 2028 年量產,可能結合 iPhone 和 Apple Watch 的生態優勢,通過深度整合硬件與 AI 技術,打造高度擬人化的智能助手。
◎ OpenAI 的機器人部門:OpenAI 以 “具身 AI” 為核心理念,將通用 AI 技術落地于物理機器人,直接與 Google DeepMind 等展開競爭。
其策略強調 AI 模型與機器人硬件的深度協同,通過強化學習和多模態訓練提升機器人在真實環境中的適應能力。
目前已推出多款原型產品,未來或在工業自動化、服務機器人等領域加速布局。

02
方案對比與結論共識
● 不同VLA方案在模型架構、動作類型和訓練目標上存在顯著差異,影響其性能與適用性。
◎ 模型架構方面,Transformer架構擅長長序列處理但資源需求大,預訓練LLM/VLM在指令理解上占優,擴散模型則在動作生成多樣性上表現突出;
◎ 動作類型方面,離散動作適用于簡單任務,連續動作更適合精確控制;
◎ 訓練目標方面,行為克隆依賴已有數據快速訓練,強化學習則優化長期獎勵。
LLM-based方案如RT-2在復雜任務和語言理解上優勢明顯,但訓練成本高、實時性不足;非LLM方案則在實時性要求高的場景中更高效。
RT系列模型從RT-1到RT-2、RTX逐步優化,引入大規模數據集和共同微調,展示了Transformer架構的潛力,并為VLA發展提供了借鑒。
共識在于,架構設計、動作表示和訓練目標的選擇需根據任務需求權衡,未來需在LLM與非LLM方案間尋求協同,以提升效率與智能性。
● VLA模型作為具身智能的關鍵技術仍面臨多重挑戰與發展機遇。
◎ 數據稀缺限制模型訓練,需開發高效數據收集與模擬技術;
◎ 運動規劃能力不足,需結合深度學習與傳統方法提升靈活性;
◎ 實時響應性有待增強,可通過優化算法與硬件加速實現;
◎ 多模態信息融合需進一步改進,跨模態學習是重要方向;
◎ 泛化能力不足,可借助元學習和域適應解決;
◎ 長時域任務執行需更智能的規劃器和常識知識;
◎ 基礎模型探索尚處初級階段,需利用大規模數據集構建通用模型;
◎ 多智能體協作需優化通信與任務分配;
◎ 安全與倫理問題日益突出,需融入常識推理與風險評估機制。
隨著技術突破,VLA將在制造業、醫療、家庭服務等領域發揮更大作用,推動機器人智能化,提升生產效率與生活質量,同時需關注倫理規范,確保技術可持續發展。
小結
上一篇:人形機器人會怎樣應用到汽車生產中?
下一篇:人形機器人2050:技術演進五階段展望
- 熱門資源推薦
- 熱門放大器推薦
 射頻電路設計
射頻電路設計 LMV821M7X/NOPB
LMV821M7X/NOPB
- LTC3835EGN 演示板、低 Iq、36Vin 同步降壓控制器
- LT3791EFE 98.5% 高效 100W (33.3V/3A) 降壓-升壓型 LED 驅動器的典型應用電路
- 使用 Analog Devices 的 LTC6990IDCB#TRMPBF 的參考設計
- STM32F103開發板-板載stlink
- 89C52RC開發板
- MIC280,MIC280 Precision Itty-bitty 熱監控器評估板
- NCP301LSN20T1 2V 窗口電壓檢測器的典型應用
- MIC2537 的典型應用:四路配電開關最終信息
- OM13524: PCA9745B demonstration board OM13524
- AM2F-1205SH52Z 5V 2W DC/DC 轉換器的典型應用













 京公網安備 11010802033920號
京公網安備 11010802033920號