“當下,我們正處于‘百模爭霸’的時代,雖說行業目前關注點主要在AI訓練端,但事實上,真正可以釋放AI價值的在推理端,AI推理會下沉到我們身邊無處不在。” Arm物聯網事業部業務拓展副總裁馬健(Chloe Ma)在Arm Cortex-A320 CPU的發布會上如是說。
她提出一個設想,假如我們生活在帶寬無限大,速率無限大的理想環境中,那么云端AI會帶給我們實時無縫的體驗。但海量數據都回傳到云端是不現實的,這種情況下,邊緣AI就勢在必行。邊緣側豐富的用例,能夠給我們帶來更多的機會。
Arm是邊緣AI生態構建的引領者,從去年4月推出Ethos-U85,到去年5月推出新的Arm Kleidi軟件和Cortex-X925/A725/A520,Arm一直關注著邊緣AI的軟件和硬件。隨著AI大模型以及蒸餾大模型的進一步發展,目前市場對邊緣AI芯片的需求不再只是算力層面,而是更高的整體能效。
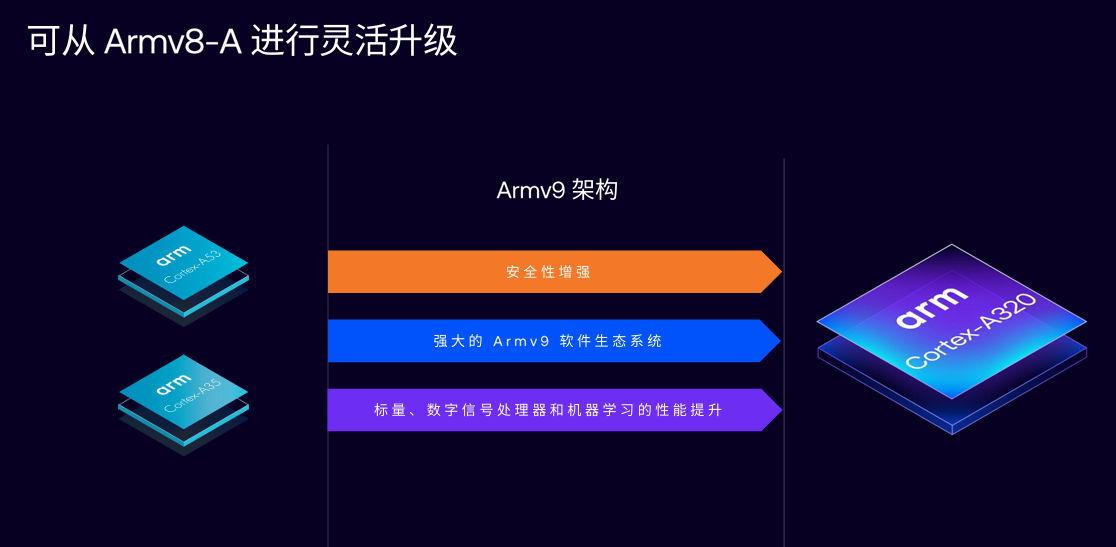
2月27日,Arm正式發布Armv9 邊緣人工智能 (AI) 計算平臺,該平臺以全新CPU Cortex A320,以及對Transformer AI網絡具有原生支持的Ethos U85 AI加速器為核心,支持運行超10億參數的端側AI模型。值得注意的是,A320不僅是一款專門為物聯網優化的超高能效CPU,也是目前最小型的Armv9-A架構CPU。
Cortex-A320:能效比顯著提升
“Cortex-A320 CPU是Arm首款基于Armv9架構的超高能效CPU,針對物聯網應用進行了專門優化,我們認為它將徹底改變邊緣 AI,因此將其作為全新計算平臺的核心組件。”Chloe Ma表示,Cortex-A320是一款基于Armv9.2-A架構的AArch64 CPU,微架構源自Cortex-A520,并經過顯著優化,以改善面積和功耗。
具體而言,在ML性能方面,Cortex-A320相較上一代超高能效Cortex-A35性能提高了十倍。在能效比方面,比V9架構的Cortex-A520 提升了50%,進一步降低了邊緣設備的能耗。在標量計算性能方面,Cortex-A320相較Cortex-A35提高了30%,帶來了更強的通用計算能力。在系統擴展方面,Cortex-A320最高可支持四核的共享集群,能根據不同需求靈活擴展,滿足各種邊緣應用需求。

Cortex-A320 提供從單核到四核配置的集群內擴展。該CPU所采用的簡化DynamIQ Shared Unit (DSU) DSU-120T,可支持僅使用Cortex-A320的集群。DSU-120T是最小的DSU實現,能夠顯著降低復雜性、面積和功耗,進而大幅提升基于Cortex-A的入門系列產品的能效。
Cortex-A320 支持高64KB的L1緩存和高達512KB的L2緩存,并且具有可連接到外部存儲器的256位AMBA5 AXI接口。L2緩存和L2 TLB可以在Cortex-A320 CPU之間共享,而實現Neon和SVE2 SIMD 技術的向量處理單元既可在單核復合體中專用,也可在雙核或四核實現中由兩個核共享。

正因為Cortex-A320也是A系列的一員,所以無論是FreeRTOS、Zephyr這種實時操作系統(RTOS),還是Linux或安卓這樣的豐富操作系統,都能高效支持。
Cortex-A320不僅能運行豐富操作系統,還具備運行實時操作系統的能力,為未來 MCU工作負載提供了更靈活的升級路徑。開發者可將現在跑在MCU上的工作負載遷移到運行在A320上的操作系統,從而獲得更強的計算能力和更高的內存靈活性。
“我們相信,Cortex-A320為IoT和嵌入式開發者提供了終極靈活性,無論開發功能豐富的操作系統還是實時操作系統,都能高效運行,滿足未來需求。”Chloe Ma如是說。

Armv9:更強大的計算能力,更多的安全功能
對于全新的Armv9邊緣AI平臺有兩個關鍵詞——一個是Armv9,一個是Cortex-A。
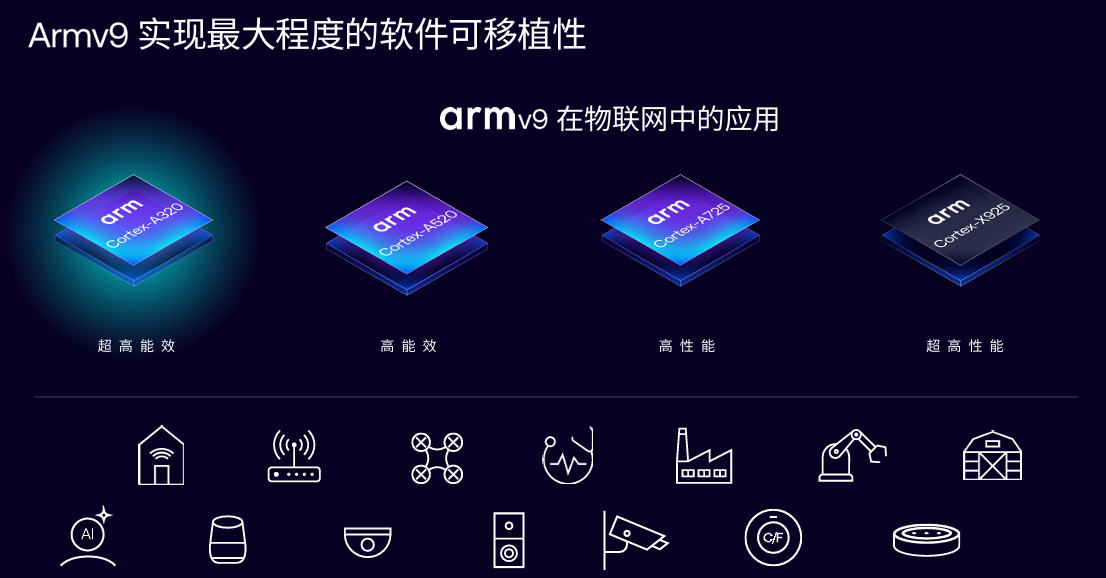
在Armv9方面,根據Chloe介紹,隨著邊緣AI在Arm平臺上持續鞏固發展,Arm為智能物聯網領域提供了最先進、全方位的Armv9 Cortex處理器家族。這一系列處理器應用廣泛,從提供極致性能的Cortex X925到適用于大規模低成本低功耗智能部署的全新A320,無論智能物聯網應用要求如何,都能找到適合的基于Armv9架構的處理器解決方案。這套解決方案為客戶和生態系統帶來了軟件兼容性優勢,Armv9軟件可在所有這些處理器上無縫運行,極大降低IoT服務部署和交付的總體擁有成本(TCO)。
Armv9架構一大突出特性是支持增強的NEON和SVE2。SVE2有助于提升DSP 任務性能,該特性使得處理復雜算法更加快速、高效。這對于AI和ML工作負載等需要高算力的應用特別有助益。借助SVE2,智能攝像頭可以更高效地處理視頻流,語音接口能夠以更低的延遲進行自然語言處理,而工業傳感器則可在保持長時間電池續航的同時,運行復雜的分析算法。
Armv9架構支持新的AI 數據類型BF16(Brain Floating Point 16-bit)。BF16格式是由Google Brain團隊提出的,旨在為人工智能(AI)和深度學習(DL)應用優化,它有時也被稱為BFloat16。BF16指數位比FP16更寬,而小數位fraction卻小。也就是說,BF16能表示的數據范圍更大,但精度變小了。
Armv9架構還新增了矩陣乘法(matrix multiplication instruction)指令,優化了 AI 和ML計算性能,加速神經網絡推理和訓練等任務。這些改進使A320成為IoT設備理想的AI計算平臺,能高效執行復雜邊緣AI任務,同時保證系統安全性和可靠性。
另外,一些開源操作系統和編譯器已支持Armv9特性,大大縮短了產品開發周期。并且,軟件應用開發版本在整個Armv9設備家族中保持兼容,例如在Cortex-A720上運行的應用,在內存允許情況下可直接搬到A320上使用,簡化了產品開發流程,減少了 IoT 生態系統伙伴在解決方案交付上的總體成本。
最后,Armv9具備先進的安全性。Cortex-A320采用了MTE、指針驗證 (PAC) 和分支目標識別 (BTI) 等先進的安全特性,并協同發揮作用,以防御各種網絡安全威脅;支持S-EL2虛擬化,增強了在同一硬件上運行的虛擬機之間的隔離性。

Cortex-A:用異構應對未來MCU工作負載
Cortex-A320作為一個將能耗比堆到極致的產品,會是這一平臺的主推產品之一,一定程度上取代一些想要做更高AI推理功能的Cortex-M產品。
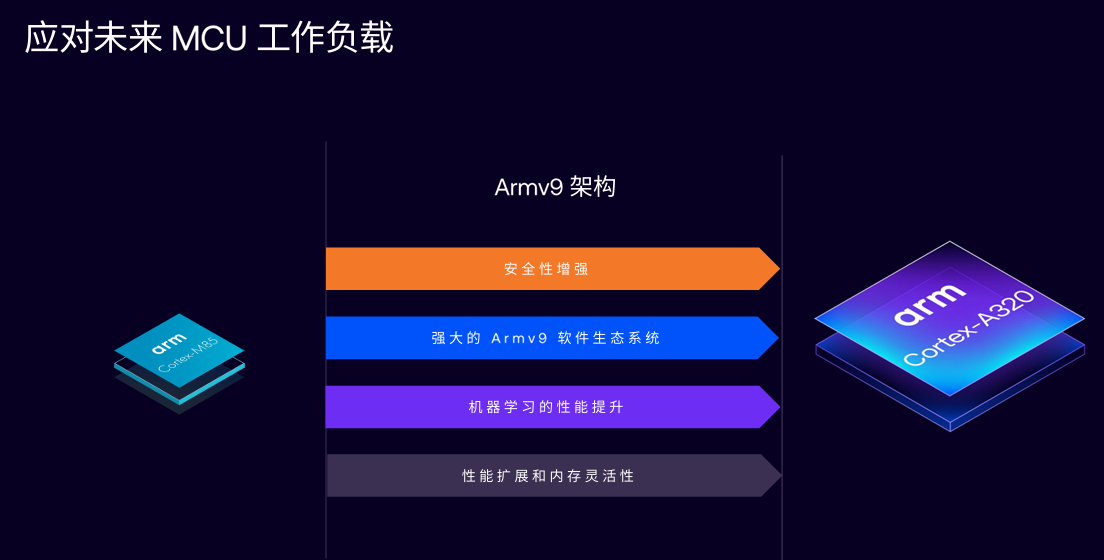
在Cortex-A方面,按照以往的邏輯來看,追求低功耗一般會選擇Cortex-M系列處理器,追求高性能則會選擇Cortex-A。但在目前邊緣AI的一些特定應用,如智能眼鏡來說,就對AI性能和低功耗有著雙重要求。而且Cortex-M的上限會更低一些,比如無法實現Cortex-A的64位性能,內存性能存在上限。
根據Chloe Ma的介紹,全新Armv9邊緣AI平臺可覆蓋多個應用場景,實現包括視覺和自然語言在內的多模態環境感知和理解,未來甚至可以運行AI智能體,實現自主規劃,在邊緣執行復雜任務。其擁有強大的計算能力,比如,Cortex-A320和Ethos-U85的組合相比Cortex-M85,擁有8倍的ML計算性能。通過這種能力,賦能邊緣AI設備輕松運行超過10億參數的大模型,助力大模型和生成式AI在物聯網領域落地。

事實上,從底層MAC 操作速率來看,A320+U85相比M85+U85的上限也更高:
| MAC/核心/時鐘周期 | 數據類型 | INT8 | INT16 | INT32 | BF16 | FP16 | FP32 |
| Cortex-M55 與 Cortex-M85 | 8 | 4 | 2 | N/A | 4 | 2 | |
| Ethos-U85 (128 MACs) | 128 | 64 | N/A | N/A | N/A | N/A | |
| Ethos-U85 (2048 MACs) | 2048 | 1024 | N/A | N/A | N/A | N/A | |
| Cortex-A320 | 32 | 8 | 4 | 8 | 8 | 4 | |
你我都知道,無論是邊緣AI還是云AI,內存性能往往決定著整個系統的上限。此外,隨著對支持更大規模多模態AI模型的硬件需求不斷增長,由于大模型參數占用空間大,且常存儲于內存中,系統對內存的需求迅速提升。因此,具備更高內存訪問性能的系統變得十分必要。
Cortex-A處理器正是為此設計,相較于Cortex-M,它支持更大的內存尋址空間,并能更靈活地管理多級內存訪問延時。同時,由于邊緣AI工作負載日益復雜,對更強大、靈活的操作系統進行系統管理的需求增加。傳統Cortex-M一般只能運行實時操作系統(RTOS)或裸跑,Cortex-A豐富的操作系統讓設備管理更靈活。
除此之外,去年發布的Cortex-M85加上Ethos-U85的Corestone物聯網參考設計平臺,已顯著提升了端側Transformer網絡的執行效率。如今,Ethos U85的驅動程序得到更新,使得Cortex-A320能夠直接驅動Ethos U85,無需額外搭載Cortex-M,這種配置被Arm稱為“直接驅動 (direct drive)”。這一更新降低了延時,讓合作伙伴可以去掉驅動U85 AI加速器的額外控制器,從而降低成本和系統復雜性。
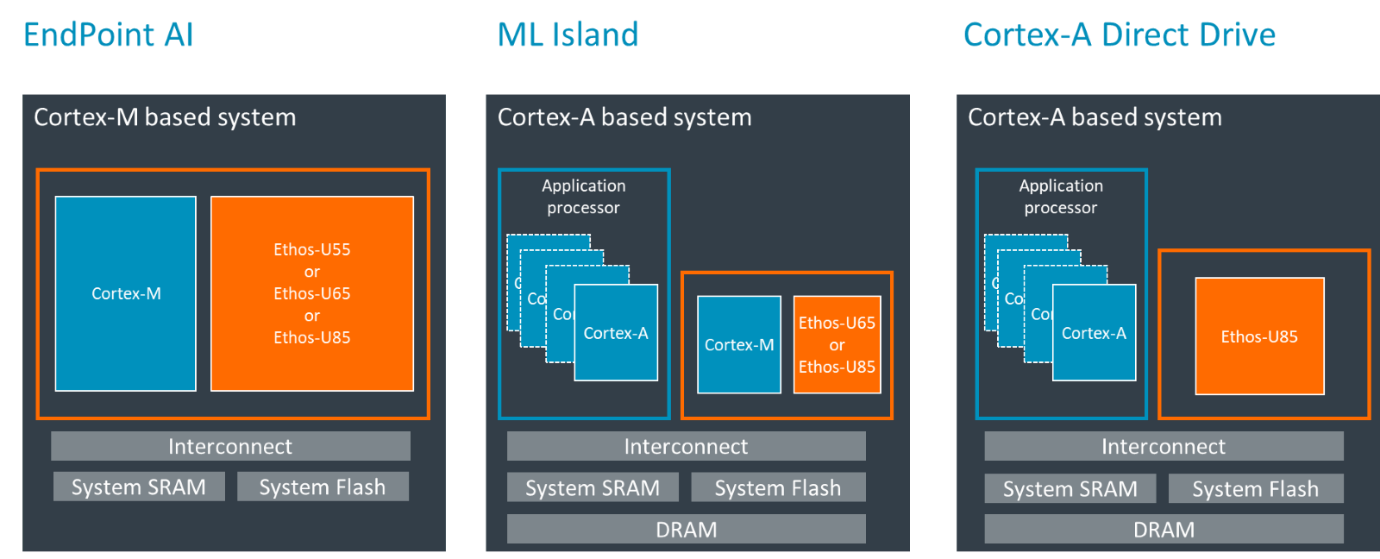
綜上,Cortex-A320與Ethos U85 的組合,是運行大模型以及需要更靈活軟件管理的邊緣AI系統的理想選擇。
讓邊緣AI在千行百業“開花”
為了讓Cortex-A320更好地進入生態,軟件也必不可少。Chloe Ma對此也介紹了Arm去年推出的Arm KleidiAI開源AI庫。得益于關鍵的ML框架和運行時集成,其優化并加速了Cortex-A320上的AI工作負載,使開發者能夠利用Armv9架構的先進功能和靈活性。Kleidi優化了跨不同工作負載的軟件級性能,以充分發揮Arm CPU上的AI加速。其高度優化的內核提升了ExecuTorch、LiteRT(前身為Tensorflow Lite)等主流 AI框架性能,從而實現了更快速的邊緣AI執行,以及CPU和NP 間順暢的工作負載靈活性。

例如,在Llama.cpp上運行微軟的Tiny Stories小語言模型時,Cortex-A320的性能提升了近70%。這一強大的組合簡化了AI開發,并加速了數十億設備的性能,使開發者能夠更輕松地在恰當的時間和位置上執行合適的AI工作負載。
“令人高興和驕傲的是,全新的邊緣 AI 計算平臺已得到行業內多家領先企業認可。”Chloe Ma表示,AWS IoT Greengrass是開源的邊緣執行程序和云服務,用于構建、部署和管理設備端軟件,目前已可在諸多基于Arm的設備上運行,并支持遠程部署、管理和升級AI功能。例如在智能制造應用場景中,可在上千臺工廠設備上實現AI功能的遠程管理和升級。在云邊協同服務場景下,安全至關重要,Armv9增強的安全特性成為IoT服務成功部署并為終端客戶創造價值的關鍵創新。因此,很高興獲得 AWS IoT 部門的支持。

Chloe Ma舉了幾個Cortex-320典型的應用場景:對于消費電子領域,Cortex-A320可以引領智能手表、智能眼鏡等智能可穿戴設備繼續創新;對于云服務商,Cortex-A320是服務器中基板管理控制器(BMC)理想的CPU 升級選擇,因為目前BMC大規模采用Cortex-A53,而Cortex-A320可帶來更高能效和管理能力;對于醫療健康領域,Cortex-A320可以革新可穿戴設備和醫療AI助手。
目前,Arm在邊緣計算平臺占據領導地位,在工業自動化、智慧家居、智慧城市等領域,OEM軟件開發者都在積極與Arm合作,構建AI推理生態系統,以釋放AI更大價值。Chloe強調,自AI發展初期,Arm技術就推動著邊緣智能創新。其Helium技術和 Ethos U AI加速器在物聯網廣泛應用,賦予數十億邊緣設備AI和ML計算能力,提升的算力讓智能軟件與模型發揮更大效能。
上一篇:Arm 發布 Cortex-A320 CPU,推出全球首個 Armv9 邊緣 AI 運算平臺
下一篇:玄鐵首款服務器級RISC-V處理器C930下月起交付
推薦閱讀最新更新時間:2025-07-04 10:49

 全國大學生電賽設計競賽電賽綜合測評報告總結
全國大學生電賽設計競賽電賽綜合測評報告總結 2025 百度人工智能創新與專利白皮書 -專利賦能大模型應用
2025 百度人工智能創新與專利白皮書 -專利賦能大模型應用 arm-linux-gcc-4.3.2.tgz
arm-linux-gcc-4.3.2.tgz 嵌入式硬件設計
嵌入式硬件設計
- 適用于汽車應用的 LT3973HMSE-3.3 3.3V 降壓轉換器的典型應用
- R_08_V30基于IPS2電機換向傳感器的設計
- 使用 Microchip Technology 的 PIC16C782 的參考設計
- 使用 LT1054CSW 基本型電壓逆變器 / 穩壓器的典型應用
- 使用 LTC3637EDHC 4V 至 76V 輸入至 1.8V 超級電容器充電器的典型應用
- 儀表用 ADC 驅動器
- EN6310QA 1A PowerSoC 電壓模式同步 PWM 降壓與集成電感器的典型應用
- STEVAL-ISV012V1,使用 L6924D 高達 5 W 太陽能電池充電器的演示板,用于單節鋰離子和鋰聚合物電池
- 適用于汽車應用的 A5974D 正降壓-升壓穩壓器的典型應用電路
- 使用 NXP Semiconductors 的 TDA2582Q 的參考設計













 京公網安備 11010802033920號
京公網安備 11010802033920號